EVRY’s business case is to develop a analytic service named CRM-S. The service offers enriched data using machine learning models to customers based on data from the euBusinessGraph.
Our main focus has been to create a generic service for running autonomous and adaptive models in the cloud as opposed to having to manually update the models and update them with new data.
In the Proof of concept, we have developed a credit risk model that predicts the chance of a company going bankrupt in the next 12 months. This has been developed using different algorithms such as regression-, random forest, AdaBoost and neural network. The models have been deployed to the analytic service.
The credit risk models are using the following data from euBusinessGraph:
- accounting information (BRREG)
- general company information (BRREG)
- bankruptcy information (BRREG)
- external remarks (external dataset)
The variables used in the models has been selected by domain experts and been examined in statistical analyses to ensure that the most significant variables are chosen. This analysis will also reveal to what degree the variables influence the models result, and if there are any multicollinearity present.
External datasets that is used in combination with euBusinessGraph requires an attribute as a shared identifier. In case of combining Norwegian data from BRREG the key identifier is the organization number.
The analytic service has been implemented using microservices (docker). We are using Kubernetes for automatic deployment, scaling and the management of the microservices.
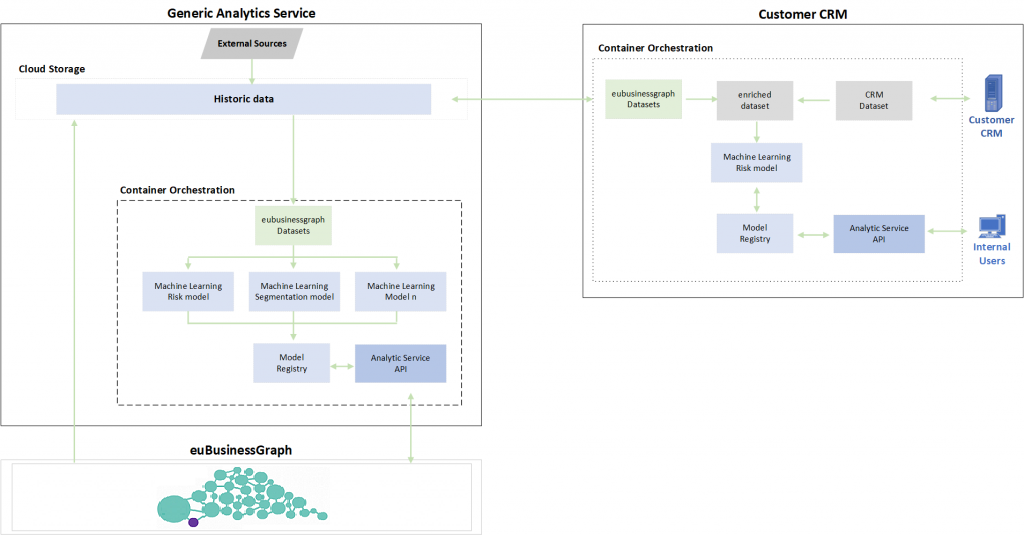
Above is an architectural overview of how the CRM-S solution works. The service is based on the following concepts;
- The euBusinessGraph consolidates company data from different companies across Europe to a single graph database.
- The cloud storage maintains all historical data that is needed to run the models. Data can be from the euBusinessGraph or from external sources. E.g. for the credit risk models a key data source are external remarks which is not available from any of the euBusinessGraphs data providers. External sources used can be restricted so that they are only available to the service itself.
- The container orchestration is where the management of the models occur. It is divided into three steps;
- Data processing: The data that is used in a model is retrieved from the cloud storage and processed so that it is ready to be consumed by the models.
- Machine learning: Training and testing of the models. The model output from this processed is stored in Azure Blob Storage, while metadata is stored in a document database.
- Deployment: The models is made available in an analytic service API and made available to the euBusinessGraph. A model registry maintains the different versions of a model.
The analytic service can also run on premise for customers who want to enrich the data in euBusinessGraph with their own data (e.g. a CRM system). In this case they will use the same orchestration as the cloud service, but they have to extract the extra information separately.
