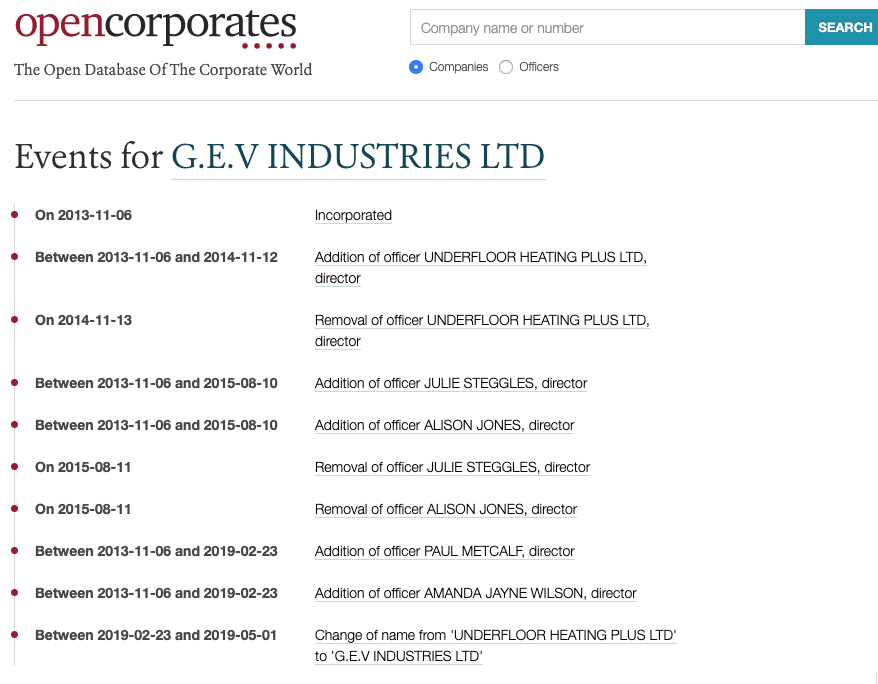
We’re proud to announce that we have now released the first public release of OpenCorporates’ new corporate events system. This has been a really substantial project that’s been more complex and more difficult than we expected, and threw up many issues and questions along the way.
But what we have now is a big step forward for OpenCorporates, and, we believe, ultimately the world’s understanding of companies.
First, the headlines:
- We’ve generated over 420 million corporate events for 170m companies.
- Around 50 thousand new events added each day on average.
- Currently features key lifecycle events, essential for monitoring company activity, including birth and death events, name and status changes, and change in officers. We’ve also started creating events from selected government gazettes.
- Events are classified for multiple domains and use cases – for example credit events, KYC events – allowing filtering for just relevant events via the API.
That’s all very good, and there’s more to come (see below), but we blogged about this way back in early 2018. Why has it taken us so long to put this into production, and release it? Two main reasons: first, our engineering approach took longer to implement than expected; second, along the way we encountered a lot of unexpected challenges that we had to overcome. We’re going to detail both of these, together with some lessons learned.
The approach
When we created corporate events, the question was whether to implement it as part of the OpenCorporates main application, or as something external.
We quickly decided upon the latter, for a couple of reasons:
- The main monolithic OpenCorporates application is a complex beast, that takes new developers a long time to get to grips with. We have a vision for how we’re going to change this in the future, but we weren’t ready to do that piece of work yet.
- Creating the events system in a microservices way that hooks into OpenCorporates would allow us to solve some of the problems about this without waiting for a separate, bigger, piece of work to complete.
- Making events part of the core app would have introduced even more complexity that would have to be unpicked when we did tackle that job. This way we have part of the system already distinct from the main app.
- We knew that we would be wanting to iterate the events system over the next year and this would allow us to do so much more easily.
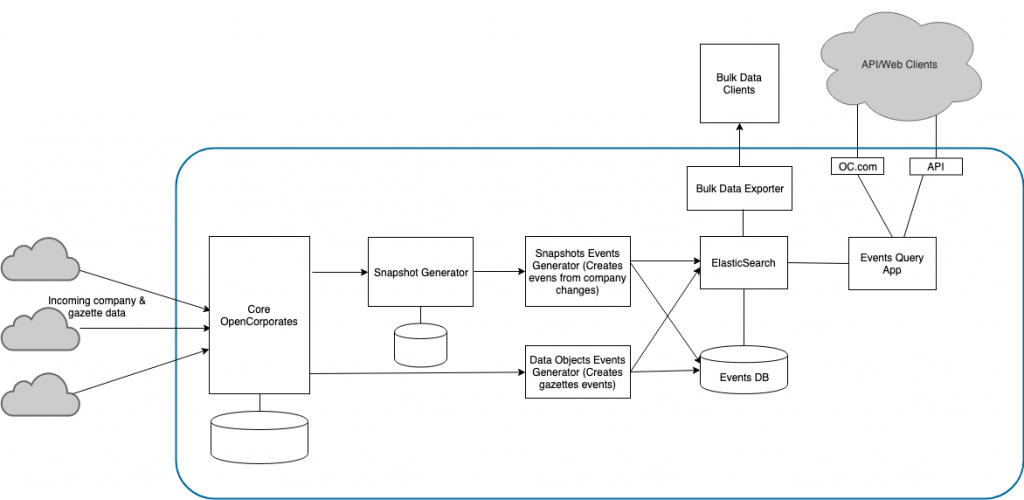
The challenges
But as anyone who’s implemented microservices systems knows, it’s no silver bullet, and to a certain extent you are trading one type of complexity for another (albeit one that’s more clearly defined and whose components are easier to work on). For example, how things are transferred from one part of the system to another; dealing with hard-to-find bugs, including race conditions and other synchronisation issues; bottlenecks; and visibility within the system as a whole.
In addition to this, we also faced a number of other issues, including:
- Issues with the underlying data from the original official source, e.g. company registers. For example, due to the importance of dates in the system (see below), problems in the dates from the registers threw up a number of roadblocks, for example dates of 0000-00-00, or far in the future. We have fed such problems back to the company registers, as part of our policy to try to fix data quality problems at source, but also have dealt with them locally too.
- Ambiguities regarding the date on which the event happened required the assumptions underlying the data model to be refined. One way events are generated is by looking at the difference between two so-called company snapshots (these are records of a company record at a point in time). In these cases we often don’t have an explicit date on which the event happened, and we then have to infer it from the snapshot dates. However, generating snapshot dates that accurately reflect the underlying data has turned out to be a highly complex issue – both technically and conceptually (more on this in a forthcoming blog post on the data model).
- The sheer scale of the data meant our original specs for the hardware, and assumptions for how the system could deal with it were out by quite a considerable margin.
Throughout the development work, we’ve been working with existing users and clients, both bulk data and API, and this has given us essential feedback on the design and delivery of the events.
Lessons learned
- We should have actually built the production system earlier (possibly without releasing it publicly) – instead we delayed trying to get the code base perfect, on small samples of data. This lead to a whole range of problems, both scale and data quality problems, that we hadn’t anticipated.
- We should have started creating events from gazettes sooner – it led to changes in the data model.
- We practiced agile, but the boundaries of the project could have been much better identified from the start, particularly the problems associated with the scale, including what equipment we would need (OpenCorporates runs on its own hardware, for the most part).
- Internal documentation – we didn’t initially do a good enough job about documenting our decisions, and, together with the length of time, this led to us spending time trying to remember what we’d decided and why.
What’s next?
As we mentioned above, we’re not finished with Corporate Events. Over the next 6-12 months we’ll be iterating them further, including:
- Adding other event types.
- Generating more types of events from gazettes (e.g. meetings, or credit events)
- Adding more gazettes (currently it’s just UK and in a day or two French gazettes).
- Adding events from filings and changes of address.
- And, if there’s demand, going back in history, to flesh out the events that happened to a company in the past.
There are also a bunch of snags that we’ll be fixing over the next 2 weeks.
Finally
We’ll be blogging shortly on the underlying data model and concepts behind corporate events – heads up, it’s going to be pretty nerdy, but will be interesting reading for those of us who love this sort of thing.
Available now on the website (you must be logged in to see them – it’s free), and via the API or as bulk data, free for public benefit users (journalists, NGOs, academics). As ever, feedback welcome.
EU Horizon 2020
This project has received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement No 732003, euBusinessGraph, an project that aims to create a crossborder knowledge graph of companies, and a set of innovative business products and services build upon the knowledge graph.
This article has first been published on opencorporates.com
